The GROUP BY clause groups the selected rows based on identical values in a column or expression. This clause is typically used with aggregate functions to generate a single result row for each set of unique values in a set of columns or expressions. The GROUP BY clause is often used in SQL statements which retrieve numerical data. It is commonly used with SQL functions like COUNT, SUM, AVG, MAX and MIN and is used mainly to aggregate data. Data aggregation allows values from multiple rows to be grouped together to form a single row. The first table shows the marks scored by two students in a number of different subjects.
The second table shows the average marks of each student. Here, the information from a table that does not satisfy the conditions is not used. So, by SQL statements, functions, operators and keywords in combination to SQL clauses makes the info access proper and manageable to deal with different tables in a database. Knowing how to use a SQLGROUP BY statement whenever you have aggregate functions is essential. In most cases, when you need an aggregate function, you must add aGROUP BY clause in your query too.

The first must contain a distinct first name of the employee and the second – the number of times this name is encountered in our database. Each sublist of GROUPING SETS may specify zero or more columns or expressions and is interpreted the same way as though it were directly in the GROUP BY clause. An empty grouping set means that all rows are aggregated down to a single group , as described above for the case of aggregate functions with no GROUP BY clause. With aggregate analytic functions, the OVER clause is appended to the aggregate function call; the function call syntax remains otherwise unchanged.

Like their aggregate function counterparts, these analytic functions perform aggregations, but specifically over the relevant window frame for each row. The result data types of these analytic functions are the same as their aggregate function counterparts. MySQL queries are SQL functions that help us to access a particular set of records from a database table. We can request any information or data from the database using the clauses or, let's say, SQL statements.

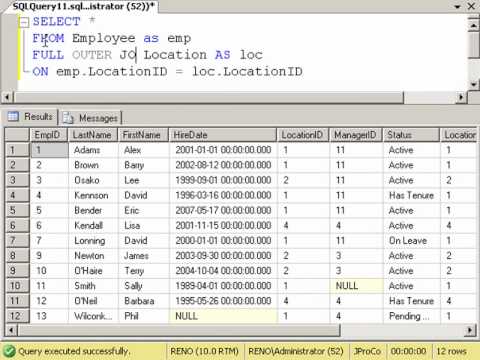
In this example, the columns product_id, p.name, and p.price must be in the GROUP BY clause since they are referenced in the query select list . The column s.units does not have to be in the GROUP BY list since it is only used in an aggregate expression (sum(...)), which represents the sales of a product. For each product, the query returns a summary row about all sales of the product. Aggregate functions operate slightly differently in aggregate queries on tables than when you use them in aggregate queries on streams, as follows. If an aggregate query on tables contains a GROUP BY clause, the aggregate function returns one result per group in the set of input rows.

Lacking an explicit GROUP BY clause is equivalent to GROUP BY (), and returns only one result for the entire set of input rows. Table functions are functions that produce a set of rows, made up of either base data types or composite data types . They are used like a table, view, or subquery in the FROM clause of a query. Columns returned by table functions can be included in SELECT, JOIN, or WHERE clauses in the same manner as columns of a table, view, or subquery. Note that the ORDER BY specification makes no distinction between aggregate and non-aggregate rows of the result set.
For instance, you might wish to list sales figures in declining order, but still have the subtotals at the end of each group. Simply ordering sales figures in descending sequence will not be sufficient, because that will place the subtotals at the start of each group. Therefore, it is essential that the columns in the ORDER BY clause include columns that differentiate aggregate from non-aggregate columns. This requirement means that queries using ORDER BY along with aggregation extensions to GROUP BY will generally need to use one or more of the GROUPING functions.

The CUBE, ROLLUP, and GROUPING SETS extensions to SQL make querying and reporting easier and faster. CUBE, ROLLUP, and grouping sets produce a single result set that is equivalent to a UNION ALL of differently grouped rows. ROLLUP calculates aggregations such as SUM, COUNT, MAX, MIN, and AVG at increasing levels of aggregation, from the most detailed up to a grand total. CUBE is an extension similar to ROLLUP, enabling a single statement to calculate all possible combinations of aggregations.

The CUBE, ROLLUP, and the GROUPING SETS extension lets you specify just the groupings needed in the GROUP BY clause. This allows efficient analysis across multiple dimensions without performing a CUBE operation. Computing a CUBE creates a heavy processing load, so replacing cubes with grouping sets can significantly increase performance.

In this case, the server is free to choose any value from each group, so unless they are the same, the values chosen are nondeterministic, which is probably not what you want. Furthermore, the selection of values from each group cannot be influenced by adding an ORDER BY clause. Result set sorting occurs after values have been chosen, and ORDER BY does not affect which value within each group the server chooses. Each window function requires an OVER clause that specifies the window top and bottom. The three components of the OVERclause provide additional control over the window. Partitioning enables you to divide the input data into logical groups that have a common characteristic.

Ordering enables you to order the results within a partition. Framing enables you to create a sliding window frame within a partition that moves relative to the current row. You can configure the size of the moving window frame based on a number of rows or a range of values, such as a time interval.

GROUP BY without aggregate function, It takes several rows and turns them into one row. If you ever need to add more non-aggregated columns to this query, you'll have to add them both to SELECT and to GROUP BY. At some point this may become a bit tedious. Any reason for GROUP BY clause without aggregation function , is the GROUP BY statement in any way useful without an accompanying aggregate function? Using DISTINCT would be a synonym in such a Every column not in the group-by clause must have a function applied to reduce all records for the matching "group" to a single record .

If you list all queried columns in the GROUP BY clause, you are essentially requesting that duplicate records be excluded from the result set. Using having without group by, A HAVING clause without a GROUP BY clause is valid and "When GROUP BY is not used, HAVING behaves like a WHERE clause. With the implicit group by clause, the outer reference can access the TE columns. Once we execute a Select statement in SQL Server, it returns unsorted results. We can define a sequence of a column in the select statement column list. We might need to sort out the result set based on a particular column value, condition etc.

We can sort results in ascending or descending order with an ORDER BY clause in Select statement. It's a mistake is to preface each of the two statements with "Similar to the WHERE clause...". The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns. This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses. Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT.
A simple GROUP BY clause consists of a list of one or more columns or expressions that define the sets of rows that aggregations are to be performed on. A change in the value of any of the GROUP BY columns or expressions triggers a new set of rows to be aggregated. ROWS - Defines a window in terms of row position, relative to the current row. For example, to add a column showing the sum of the preceding 5 rows of salary values, you would query SUM OVER . The set of rows typically includes the current row, but that is not required.

Which SQL Query Must Have A Group By Clause When Used With Said Function You can use either numeric or string expressions as arguments for comparison functions. (String constants must be enclosed in single or double quotes.) The expressions can be literals or values fetched by a query. Comparison functions are most often used as filtering conditions in WHERE clauses, but they can be used in other clauses. The LIMIT clause will stop processing and return results when it satisfies your requirements.

The OMIT RECORD IF clause is a construct that is unique to BigQuery. It is particularly useful for dealing with nested, repeated schemas. It is similar to a WHERE clause, but different in two important ways. First, it uses an exclusionary condition, which means that records are omitted if the expression returns true, but kept if the expression returns false or null.

Second, the OMIT RECORD IF clause can use scoped aggregate functions in its condition. To find the GROUP BY level of a particular row, a query must return GROUPING function information for each of the GROUP BY columns. If you do this using the GROUPING function, every GROUP BY column requires another column using the GROUPING function. For instance, a four-column GROUP BY clause must be analyzed with four GROUPING functions.

This is inconvenient to write in SQL and increases the number of columns required in the query. When you want to store the query result sets in tables, as with materialized views, the extra columns waste storage space. How will GROUP BY clause perform without an aggregate function?

Every column not in the group-by clause must have a function applied to reduce all records for the matching "group" to a single record . This clause is generally used with aggregate functions that allow grouping the query result rows by multiple columns. The aggregate functions are COUNT, MAX, MIN, SUM, AVG, etc. Expression_n Expressions that are not encapsulated within the MAX function and must be included in the GROUP BY clause at the end of the SQL statement. Aggregate_expression This is the column or expression from which the maximum value will be returned.

Tables The tables that you wish to retrieve records from. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected. Can be used to simplify a query that needs many GROUP BY levels. The function argument is a list of one or more columns or expressions in parentheses. The result is an integer consisting of "n" binary digits, where "n" is the number of parameters to the function.

For each result row of the grouped query, the digit corresponding to the nth parameter of the GROUPING function is 0 if the result row is based on a value of the nth parameter, else 1. The WHERE clause, sometimes called the predicate, filters records produced by the FROM clause using a boolean expression. Multiple conditions can be joined by boolean AND and OR clauses, optionally surrounded by parentheses—()— to group them.

CROSS JOINcan return a large amount of data and might result in a slow and inefficient query or in a query that exceeds the maximum allowed per-query resources. When possible, prefer queries that do not use CROSS JOIN. For example, CROSS JOIN is often used in places where window functions would be more efficient. The WITHIN keyword causes the aggregate function to aggregate across repeated values within each record. For every input record, exactly one aggregated output will be produced.

This type of aggregation is referred to as scoped aggregation. Since scoped aggregation produces output for every record, non-aggregated expressions can be selected alongside scoped-aggregated expressions without using a GROUP BY clause. FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query.

How To Resolve ORA Not a GROUP BY Expression, when you are using an aggregate function. Common aggregate functions include SUM, AVG, MIN, MAX, and COUNT. The following question is not new, but keeps being repeated over time. "How do we select non-aggregate columns in a query with a GROUP BY clause? In this post we will investigate this question and try to answer it in a didatic way, so we can refer to this post in the future.

This blog provides an overview of MySQL window functions. A window function performs an aggregate-like operation on a set of query rows. However, whereas an aggregate operation groups query rows into a single result row, a window function produces a result for each query row. On streams, an aggregate query must contain an explicit GROUP BY clause on a monotonic expression based on rowtime.

Without one, the sole group is the whole stream, which never ends, preventing any result from being reported. Adding a GROUP BY clause based on a monotonic expression breaks the stream into finite sets of rows, contiguous in time, and each such set can then be aggregated and reported. In the example above, the WHERE clause is selecting rows by a column that is not grouped , while the HAVING clause restricts the output to groups with total gross sales over 5000. Note that the aggregate expressions do not necessarily need to be the same in all parts of the query. If the WITH ORDINALITY clause is specified, an additional column of type bigint will be added to the function result columns. This column numbers the rows of the function result set, starting from 1.

A table reference can be a table name (possibly schema-qualified), or a derived table such as a subquery, a JOIN construct, or complex combinations of these. If more than one table reference is listed in the FROM clause, the tables are cross-joined (that is, the Cartesian product of their rows is formed; see below). CUBE generates the GROUP BY aggregate rows, plus superaggregate rows for each unique combination of expressions in the column list. The order of the columns specified in CUBE() has no effect.

COVAR_POP Computes the population covariance of the values computed by numeric_expr1 and numeric_expr2. COVAR_SAMP Computes the sample covariance of the values computed by numeric_expr1 and numeric_expr2. EXACT_COUNT_DISTINCT Returns the exact number of non-NULL, distinct values for the specified field. FIRST Returns the first sequential value in the scope of the function. GROUP_CONCAT('str' ) Concatenates multiple strings into a single string, where each value is separated by the optional separator parameter. If separator is omitted, BigQuery returns a comma-separated string.

When the ROLLUP function is used, BigQuery adds extra rows to the query result that represent rolled up aggregations. All fields listed after ROLLUP must be enclosed in a single set of parentheses. In rows added because of the ROLLUPfunction, NULL indicates the columns for which the aggregation is rolled up. CUBE, ROLLUP, and GROUPING SETS do not restrict the GROUP BY clause column capacity. The GROUP BY clause, with or without the extensions, can work with up to 255 columns. However, the combinatorial explosion of CUBE makes it unwise to specify a large number of columns with the CUBE extension.